KNN
In this lab, the purpose was to train a KNN to recognise humour on faces.
In that purpose, we had a big database of 48*48 pixels pictures, and a start of a code on jupiter. It was the first time for me on this software and I found it really great, even as I am now used to google colab. Indeed, the capacity of doing it all in the machine is interesting. However, computer power issues of course occurred.
Once again I worked with Cecilia. It was really hard to succeed in this lab as we had so little information. Fortunately, this lab is close on some part with another project I am working on.
the Data
A model needs data. We need at first to take the data out of the raw pictures so it can be used for the training.
import os
path="TD4-database/train/"
folders=os.listdir(path)
print(folders)
####
import matplotlib.pyplot as plt
import os
from datetime import datetime
import numpy as np
now = datetime.now()
current_time = now.strftime("%H:%M:%S")
print("Current Time =", current_time)
lable_list=[] # save the emotion lable [0 'angry', 1'disgust', 2'fear', 3'happy', 4'neutral', 5'sad', 6'surprise']
imgs=[] #save the imamges
for i in range(len(folders)):
path_emotion=path+folders[i]
filenames=sorted(os.listdir(path_emotion))
#print("..................")
#print(filenames)
for j in range(len(filenames)):
lable_list.append(i)
img=plt.imread(path_emotion+"/"+filenames[j])
imgs.append(img)
now = datetime.now()
current_time = now.strftime("%H:%M:%S")
print("Current Time =", current_time)
We now have two list “lable_list” and “imgs' of 28709 elements (number of pictures for the training).
This importation was not too hard for us.
The network
Here is simply the code to train the network :
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(train_images, lable_list)
However, this is where issues occured.
Dimension issues
Our first issue was that the dimension of “imgs” as input was too big for the model :

The dimension is indeed two for each picture (48*48), so 3. We then did our best to give a 2 dimension array :
train_images = []
import cv2
for i in range(len(imgs)):
train_images.append(cv2.resize(imgs[i], (48, 48)).flatten())
We now have a list of shape (28709, 2304) because 2304 = 48*48.
And now it worked !
The test data
We now had to do all of this again for the test data. We saw that the number of success was vey law. A solution has to be found.
Local Binary Patterns
As asked by our teacher, we implemented an LBP method with “skimage” package. We apply this method to each picture :
import skimage.feature
for i in range(len(lable_list)):
imgs[i] = skimage.feature.local_binary_pattern(imgs[i], 8,1.0,method='var')
However, it occured the ‘var’ method has issues !

Indeed, ‘nan’ values are created in the picture and the model cannot interpret them. I looked for very long on the internet without finding a relevant solution.
Therefore, I tried all the others methods instead of “var” :
However, the results were still not good enough.
So I tried another solution with the “var” method : replace all the “nan” by 0.
import math
compteur = 0
n = len(train_images[0])
long = len(train_images)
for i in range(long):
for j in range(n):
if math.isnan(train_images[i][j]):
compteur += 1
train_images[i][j] = 0
compteur
The “compteur” shows that there were 252616 like this. The model was then capable of working again, but still the results are no good.
Results
1/7 = 0.14, so random evaluation should be around this number (I founded such results during my tests).
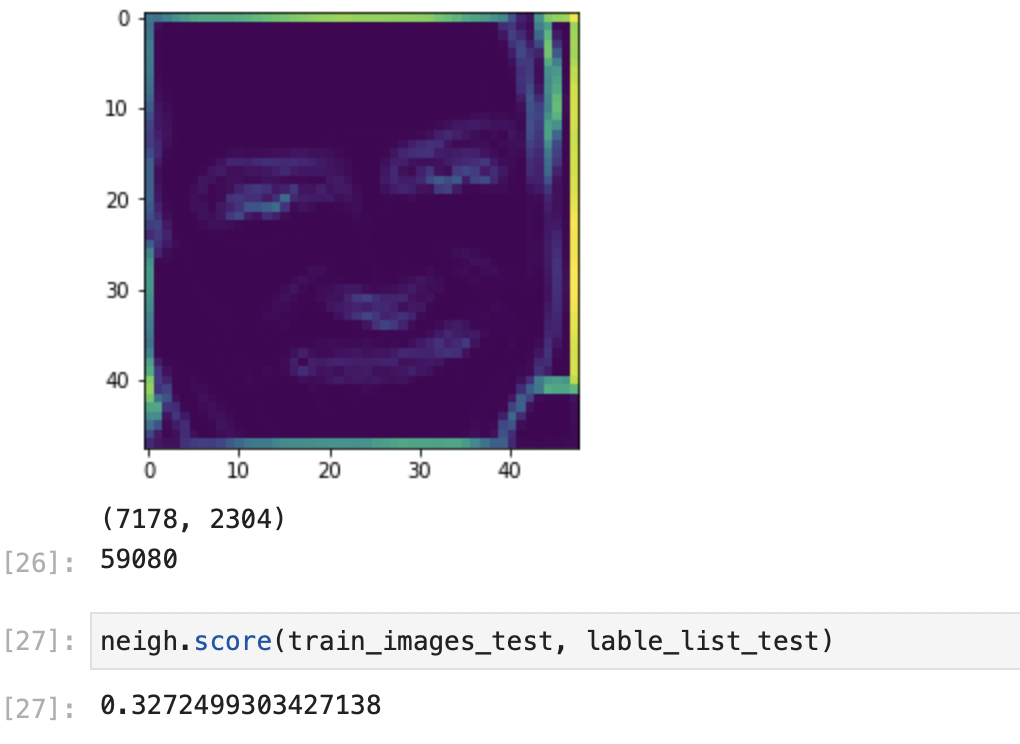
Here, the result is around 0.32. We then can conclude there are some results. However still, the model is not efficient enough. Of course, the ‘nan’ issues must be part of the cause as putting randomly pixels to 0 cannot be such a relevant solution, but we could not do anything else as many pictures in the data base given are simply broken.