Reinforcement Learning
Colab link
Here you can find all my code : https://colab.research.google.com/drive/1KHNH1-sgeiHZoaU9Gn2laJl_o-Y3d1z7
Introduction
After one class about reinforcement learning, this lab purpose is to implement a method to resolve the “Cart pole” problem.
Note that a real RL application would use a framework with most of the tools, here we want to understand how it really works.
Theory
As a reminder, reinforcement learning is a teaching by experience. We test different actions and see what happens then. There is then a delay between action and reward. We use a ‘reward’ to solve this.
We have to note differences between On and Off policies. The first is used to make the programm learn by its own mistakes whereas the other uses data to learn from the errors of others. An exemple could be filming many chests plays and see actions professionals make.
To learn, we have a first main algorithm : the monte carlo one. It has as main advantage that it does not need any model to explore. However, it waits until the end to update the value. Therefor, it could never reach a second step or take very long !
Another method is the temporal difference one that compute it’s state accordingly to the difference between the state and the prediction at each step.
SARSA
For this lab, we will at first use SARSA which is an On-policy, temporal difference method. #For this lab, we will use Q-Learning which is an O-policy, temporal difference method.
The lab
We use Gym framework for this lab : https://gym.openai.com
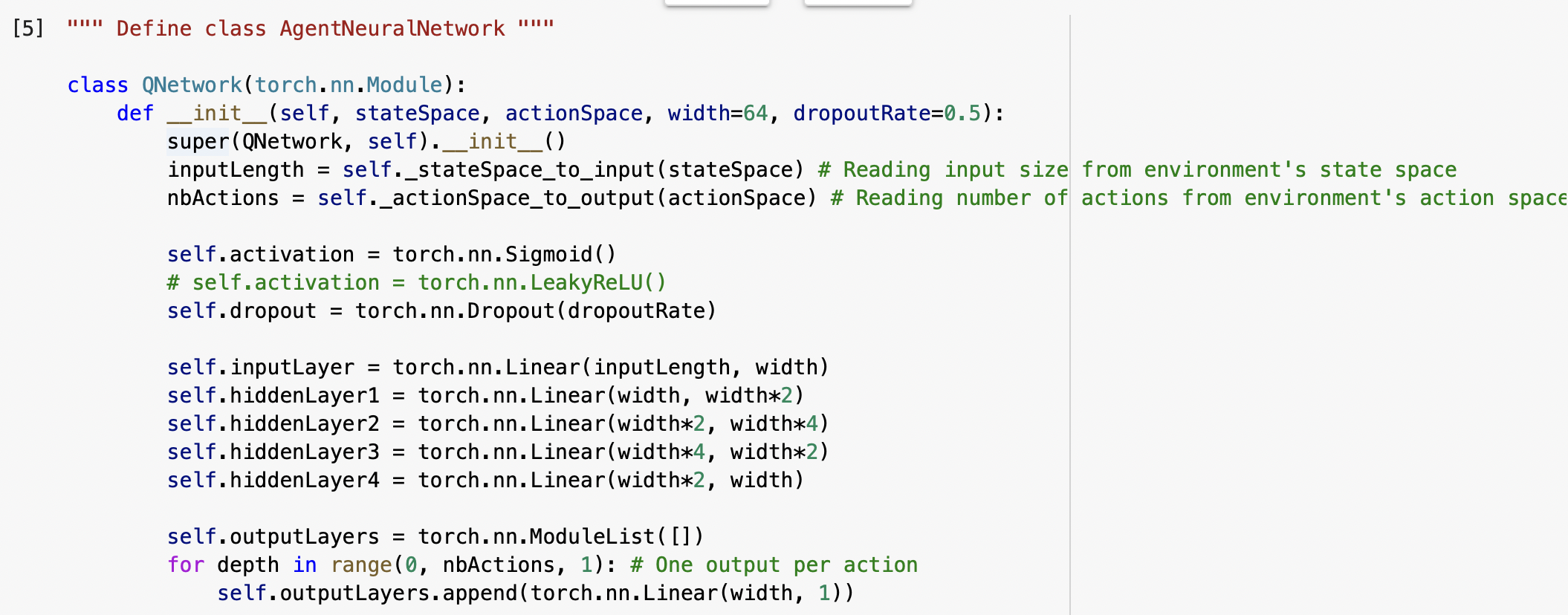
We start by buidling the network. We see that there is one layer per possible action.
We then defined a “doer” which is the function that will do the action. We actually implement their the formula of the TD method and the different parameters.
Then there is the class ‘transition’ that save all the different parameters each time (state, action done, …).
After that, the ‘Experience Replay’ class will actually contain all the transitions made to arrive at a certain point.
We now can create a ‘learner’ which is a class that will learn from the experience saved right before with the replay. We here implement the algorithm values thanks to all the parameters defined before.
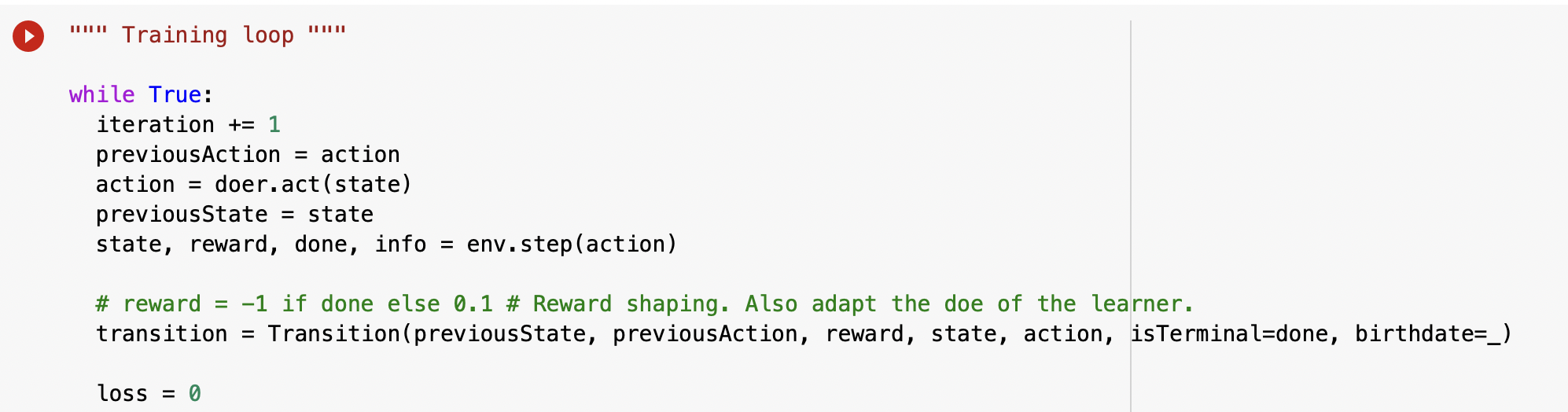
Then we make all of this loop to increase data and we hope accuracy.
Note : we use a ‘while true’ loop that never stops. We have to make it stop when we want to move forward. Of course the more you train it, the better the model must be.
We can then visualize thanks to ‘gym’ the output (different transitions made or for instance video of the agent).
My tests
training loop : change initaile trainning or change network : add depth or some capacity
goal : get score as high as possible
-
The basic one
Let’s start with this simple architecture :
We use the SARSA algorithm and those parameters :
After 5000 iterations, I obtain a score of 22,48.
-
Other reward tested
I changed the reward to a fixed one at 0.2.

After 5000 iterations, I obtain a score of 31.99.
With a reward shaping (‘reward = -1 if done else 0.1’) I got 37.5 !
I tried several over parameters. For instance : reward = -2 if done else 0.3 gave 22, reward = -2 if done else 0.01 gave 28 and reward = -4 if done else 0.1 only 19.
-
other structure
Here I tested to remove some layers of the system, results were clearly bad :

Finally, I tried to make the network deeper, but the results were disappointing :

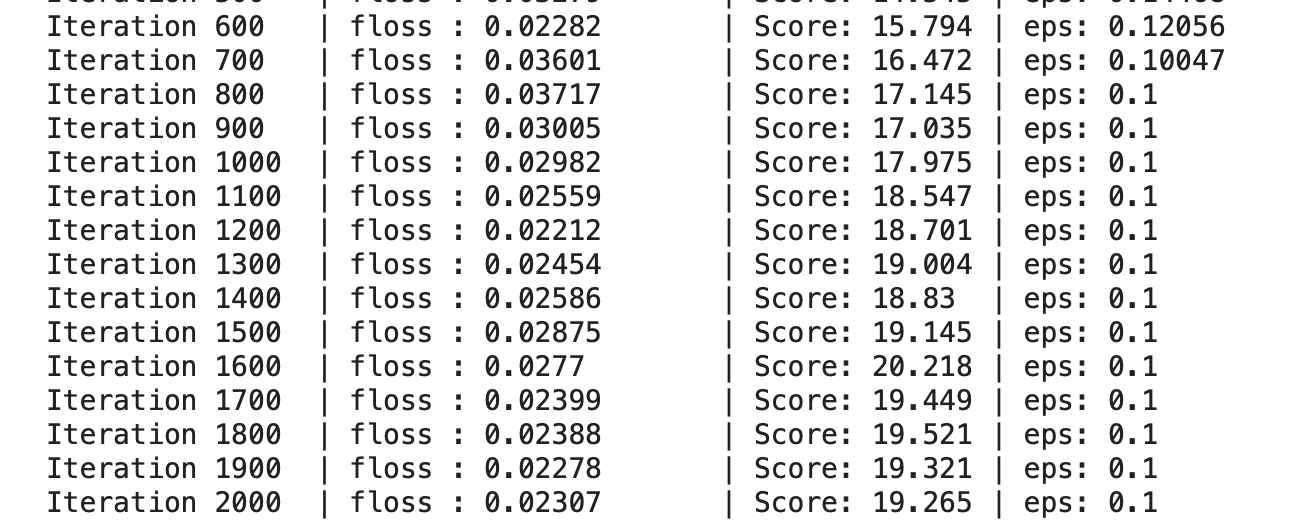
Note : the time it took to compute was much longer. It is logical but still the difference was significant.